Пошаговый how to восстановления данных из MongoDB
Зачем этот how to
Нередки ситуации когда появляется необходимость восстановить данные из бэкапа Базы данных. В системе MyBPM основной Базой данных является MongoDB, но она не единственный сервис, который хранит данные. Данные так же хранятся в kafka, Elasticsearch, postgresql и zookeeper. Так же следует учесть, что данное руководство показывает как восстановить данные внутри системы, но для полного бэкапирования лучше всего подходят другие инструменты. Например snapshot виртуальной машины и подобные. Если все-таки mongo используется для бэкапа , то помимо монго так же требуется сохранить конфиги из zookeeper.
Изначальные условия перед началом
Виртуальная машина или сервер с достаточным количеством памяти (за основу лучше взять ресурсы использовавшиеся в системе с которой снят бэкап)
Инициализированный кластер kubernetes
Установленный docker-ce
Дамп базы данных Монго
Файлы-манифесты для деплоя сервисов составляющих MyBPM
Дамп конфигов zookeeper
Порядок действий
1) Деплой - остановка сервисов. 2) Зачистка и загрузка дампа в БД монго. 3) Загрузка конфигов zookeeper. 4) Деплой сервисов - подготовка к миграции. 5) Настройка миграции/ 6) Запуск миграции. 7) Проверка миграции.
1 - Деплой - остановка сервисов.
Первым делом необходимо запустить систему, для того чтобы создались все необходимые таблицы в БД , они в этот момент не будут содержать информации.
Cоздаем namesapce
kubectl create ns tcore2
В данном случае неймспейс “tcore2”, у вас будет другой, подсмотреть его можно в любом из yaml с которых разворачивается система в одноименном параметре.
Далее переходим в директорию в которой находятся yaml файлы. И запускаем-деплоим yaml-ы, в этот момент сервисы создают структуры данных и таблицы.
cd soft/Stand-test/
Производим логин в регистр MyBPM
docker login hub.mybpm.kz
Вводим свои данные для авторизации в регистре MyBPM/
При удачном логине Docker сгенерирует файл-конфиг. В домашней директории пользователя под кем происходил логин.
На основе полученного конфига docker создаем pullImageSecret
kubectl create secret generic -n tcore2 mybpm-docker-hub \
--from-file=.dockerconfigjson=~/.docker/config.json \
--type=kubernetes.io/dockerconfigjson
И деплоим манифесты в последовательности возрастания нумерации директорий и файлов в них.
kubectl apply -f ./01-pg/10-pg.yaml -f ./02-mongo/00-configmap-init.yaml -f ./02-mongo/10-mongo-main.yaml -f ./02-mongo/20-mongo-express-main.yaml -f ./03-elastic/10-elastic.yaml -f ./04-zookeeper/10-zookeeper.yaml -f ./04-zookeeper/20-zoo-navigator.yaml -f 05-kafka/10-kafka.yaml -f 05-kafka/20-kui.yaml -f ./07-mybpm-api/10-mybpm-api.yaml -f ./08-mybpm-web/10-mybpm-web.yaml
Проверяем все ли корректно задеплоилось.
kubectl get pods -n tcore2
Вывод команды должен быть таким :
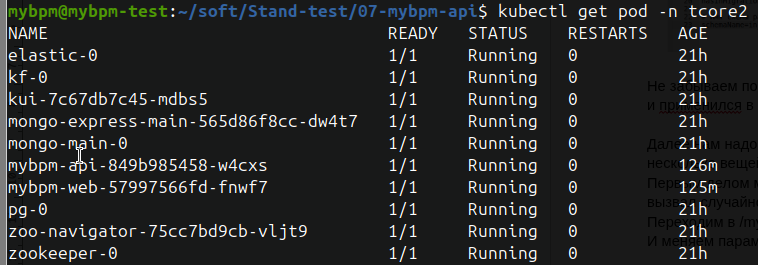
Статус везде должен быть READY 1/1
Далее останавливаем задеплоенные сервисы системы
kubectl delete -f ./01-pg/10-pg.yaml -f ./02-mongo/00-configmap-init.yaml -f ./02-mongo/10-mongo-main.yaml -f ./02-mongo/20-mongo-express-main.yaml -f ./03-elastic/10-elastic.yaml -f ./04-zookeeper/10-zookeeper.yaml -f ./04-zookeeper/20-zoo-navigator.yaml -f 05-kafka/10-kafka.yaml -f 05-kafka/20-kui.yaml -f ./07-mybpm-api/10-mybpm-api.yaml -f ./08-mybpm-web/10-mybpm-web.yaml
проверяем что все остановлено
kubectl get pods -n tcore2
Нужно дождаться пока вывод команды не станет таким

2 - Зачистка и загрузка дампа в БД монго.
Далее зачищаем директорию в которой хранятся данные mongo, задаем права, распаковываем архив с дампом.
sudo rm -rf /k8s-volumes/mongo-main/*
cp ./mongo-21-11-2025-core2.zip /k8s-volumes/mongo-main/
unzip /k8s-volumes/mongo-main/mongo-21-11-2025-core2.zip
sudo chmod -R 777 /k8s-volumes/mongo-main
Командой выше предполагается, что дамп лежит в домашней директории и называется mongo-21-11-2025-core2.zip и архив копируется в k8s-volumes стандартная директория для volume монго в кластере в типовом yaml. Соответственно, если у вас другие директории то подставляйте свои.
Следующим шагом необходимо запустить БД монго . Поскольку восстановление из дампа в БД , в случае если у вас довольно объемная БД занимает достаточно много ресурсов , в особенности по оперативной памяти, то подправляю в манифесте 10-mongo-main.yaml параметр отвечающий за выделение памяти
Было resources: limits: memory: 3Gi
Выделяю всю доступную в текущий момент память resources: limits: memory: 14Gi
И запускаем Монго.
kubectl apply -f ./02-mongo/00-configmap-init.yaml -f ./02-mongo/10-mongo-main.yaml
проверяем что монго стартовала.
kubectl get pods -n tcore2

Далее переходим в под mongo-main-0 и запускаем восстановление базы из дампа
переходим в pod
kubectl exec -it mongo-main-0 bash
Запускаем восстановление Бд (Внутри Pod-а директория /data/db/ ссылается на /k8s-volimes/mongo-main основного хоста, в которой находится разархивированный архив дампа монго. Это настроено с помощью volume).
mongorestore /data/db/mongo-21-11-2025-core2/
Дожидаемся окончания процесса , он может занять продолжительное время, в зависимости от размера БД.
При завершении будет вывод вида:
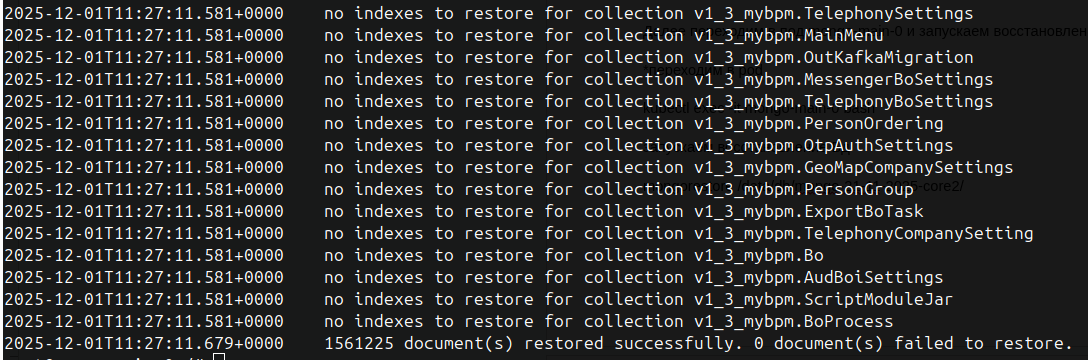
вводим для того чтоб отключиться от pod-a
exit
3 - Загрузка конфигов zookeeper.
В случае если если у вас есть бэкап zookeeper, то в в этот момент необходимо загрузить в сервис zookeeper. Когда снимается дамп конфига zookeeper системы, необходимо скопировать именно /mybpm_v1_3 , поскольку, в зависимости от настроек kafka, zookeeper может использоваться так же для синхронизации nod-ов kafka.
Пример снятия-восстановления бэкапа настроек системы из zookeeper с помощью zk-navigator.
Переходим в web интерфейс zk-navigator (адрес это будет адрес вашей control-center nod-ы ), порт посмотреть можно в yaml манифесте ./04-zookeeper/20-zoo-navigator.yaml в разделе сервиса параметр nodeport.
Выглядит этот параметр так
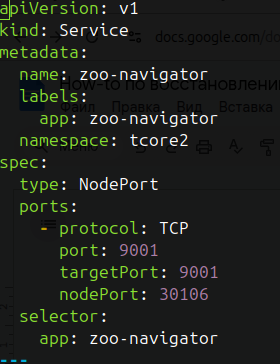
в моем случае это порт 30106
Запускаем zookeeper
kubectl apply -f ./04-zookeeper/10-zookeeper.yaml - f ./04-zookeeper/20-zoo-navigator.yaml
После чего переходим в браузере http://XX.XX.XX.XX:30106 и попадаем в интерфейс(Где ХХ.ХХ.ХХ.ХХ ip адрес вашего master(control-centre) в kubernetes).
В интерфейсе щелкнув на 3 точки напротив интересующего каталога можно сделать бэкап выбрав пункт export, бэкап загрузится в папку “загрузки” вашего компьютера через браузер.
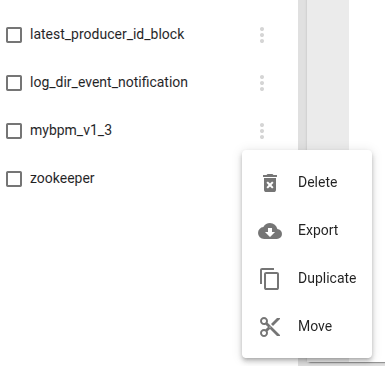
Для восстановления в этом же интерфейсе в верхней левой части нажимаем пиктограмму облака со стрелкой вверх.
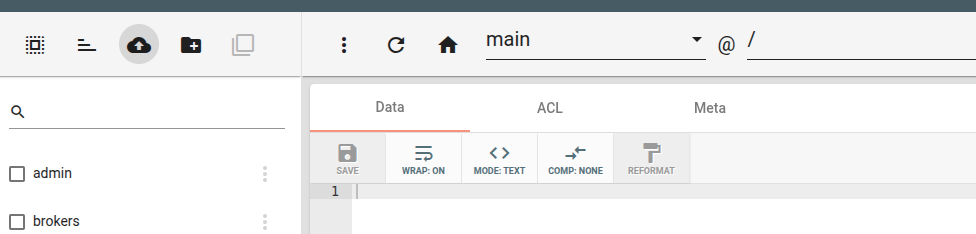
Затем в открывшемся диалоговом окне с помощью Browse выбираем файл с настройками для загрузки.
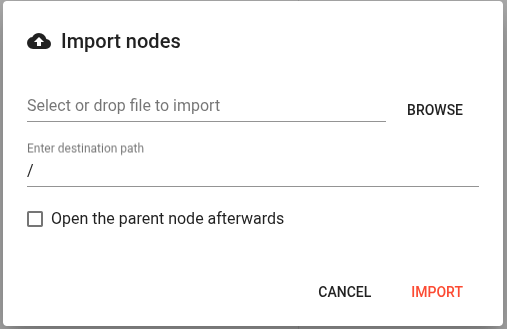
И завершаем нажав import
У вас должен появиться сохраненный ранее каталог.
В случае если сохраняли полный дамп , то после восстановления следует удалить все каталоги до запуска системы, кроме mybpm_v1_3 , zookeeper.
4 - Деплой сервисов - подготовка к миграции.
Далее деплоим все сервисы не забыв вернуть настройки по памяти для сервиса монго.
kubectl apply -f ./01-pg/10-pg.yaml -f ./02-mongo/00-configmap-init.yaml -f ./02-mongo/10-mongo-main.yaml -f ./02-mongo/20-mongo-express-main.yaml -f ./03-elastic/10-elastic.yaml -f ./04-zookeeper/10-zookeeper.yaml -f ./04-zookeeper/20-zoo-navigator.yaml -f 05-kafka/10-kafka.yaml -f 05-kafka/20-kui.yaml -f ./07-mybpm-api/10-mybpm-api.yaml -f ./08-mybpm-web/10-mybpm-web.yaml
Проверяем что все корректно запустилось
kubectl get pods -n tcore2
Вывод команды, как уже говорилось раннее должен быть таким
5 - Настройка миграции.
Для дальнейших действий будут необходимы учетная запись пользователя, кем создана компания (аккаунт) в системе MyBPM, этот пользователь является суперадмином для данного аккаунта.
Еще одна база данных postgresql для настройки in миграции, поскольку на ее основе и создано восстановление из mongo. База данных Postgresql может находится как на внешнем сервере БД, так и на локальном, который используется системой, но в другой БД. Описывать буду второй вариант, но принципиально настройка не отличается от внешнего сервера.
Создаем базу данных postgres , которую будем использовать для миграции .
Для этого подключаемся к pod-у pg , для создания новой БД.
kubectl -n tcore2 exec -it pg-0 bash
Внутри меняем пользователя на postgres и подключаемся к бд в консольном режиме.
su postgres
psql
Просматриваем текущие БД
\l
И видим следующие базы :
Name | Owner|Encoding|collate|Ctype|Access privileges mybpm_aux1| mybpm | UTF8| en_US.utf8 | en_US.utf8 | =Tc/mybpm | | | | | mybpm=CTc/mybpm postgres | postgres| UTF8| en_US.utf8 | en_US.utf8 | template0| postgres| UTF8| en_US.utf8 | en_US.utf8 | =c/postgres | | | | | postgres=CTc/postgres template1| postgres| UTF8| en_US.utf8 | en_US.utf8 | =c/postgres | | | | | postgres=CTc/postgres
Теперь необходимо создать Базу данных и пользователя.
Я буду создавать Базу со следующими именами и свойствами.
username: in_migration
password: g56gth65h7786jhQAZXSW234
datbaseName: in_migration
schema: in_tables
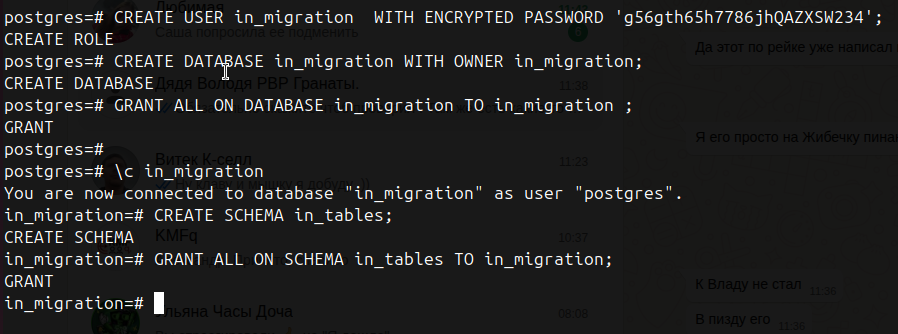
Для этого выполним в psql
CREATE USER in_migration WITH ENCRYPTED PASSWORD ‘g56gth65h7786jhQAZXSW234’;
CREATE DATABASE in_migration WITH OWNER in_migration;
GRANT ALL ON DATABASE in_migration TO in_migration ;
Далее создаем схему , для этого переключаемся на только что созданную базу
\c in_migration
И выполним
CREATE SCHEMA in_tables;
GRANT ALL ON SCHEMA in_tables TO in_migration;
Результат выполнения будет примерно таким
Далее необходимо зайти в браузере в систему, под пользователем который является суперадмином который создавал аккаунт (компанию). Это нужно для того чтобы узнать код аккаунта. А также создать минимальное количество объектов для миграции, что необходимо для создания и заполнения таблиц.
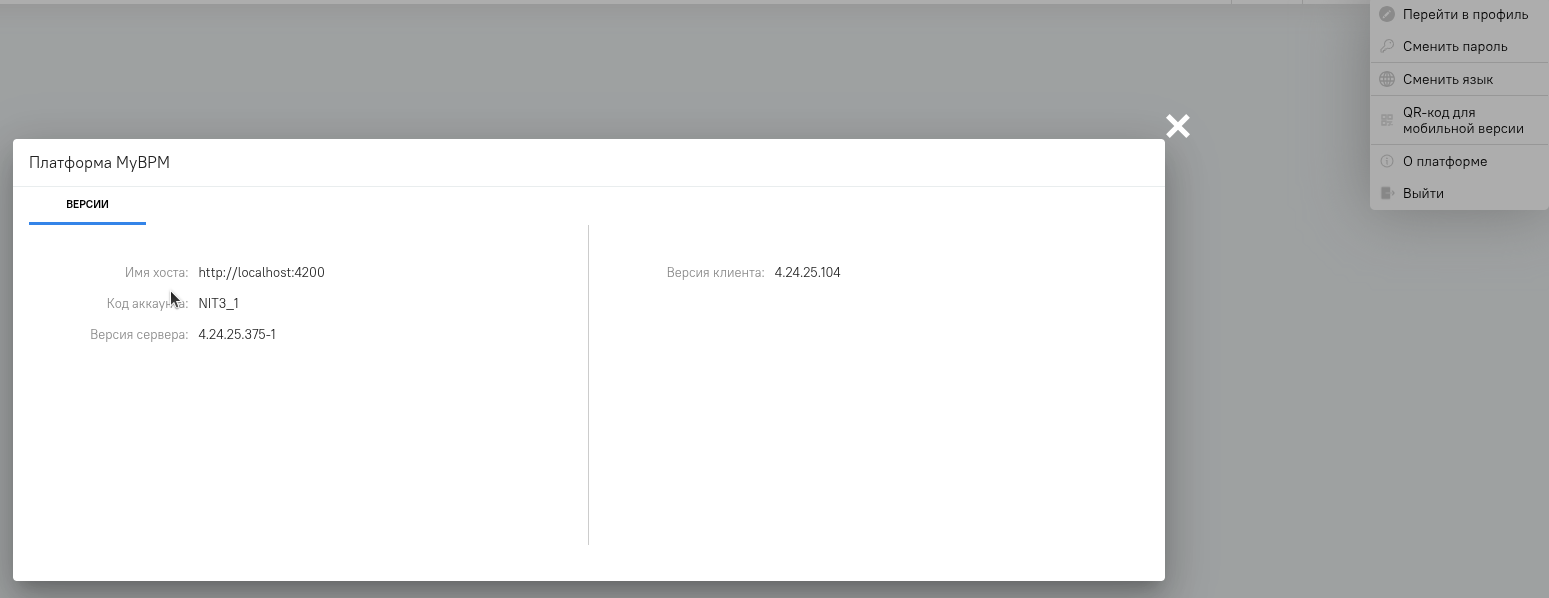
Переходим в интерфейс системы, логинимся.
После логина кликаем сверху справа на пиктограмме пользователя и в выпадающем списке выбираем “О программе”, в открывшемся окне можно увидеть код аккаунта (компании) который в последующем нам понадобится. В данном случае он NIT3_1.
Далее нажмем 3 полосочки вверху и нажать карандашик возле пункта в меню “Бизнес Объекты”. Затем нажмем зеленый плюсик и в выпадающем списке выберем “бизнес объект”
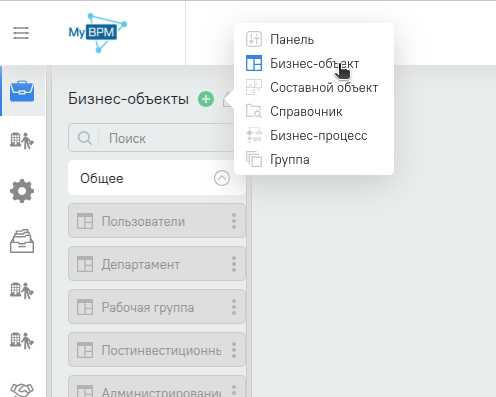
После чего введем произвольное название нового объекта и проверим,что поменялся код, для этого перейдем в шестеренку и посмотрим поле “код бизнес объекта”‘
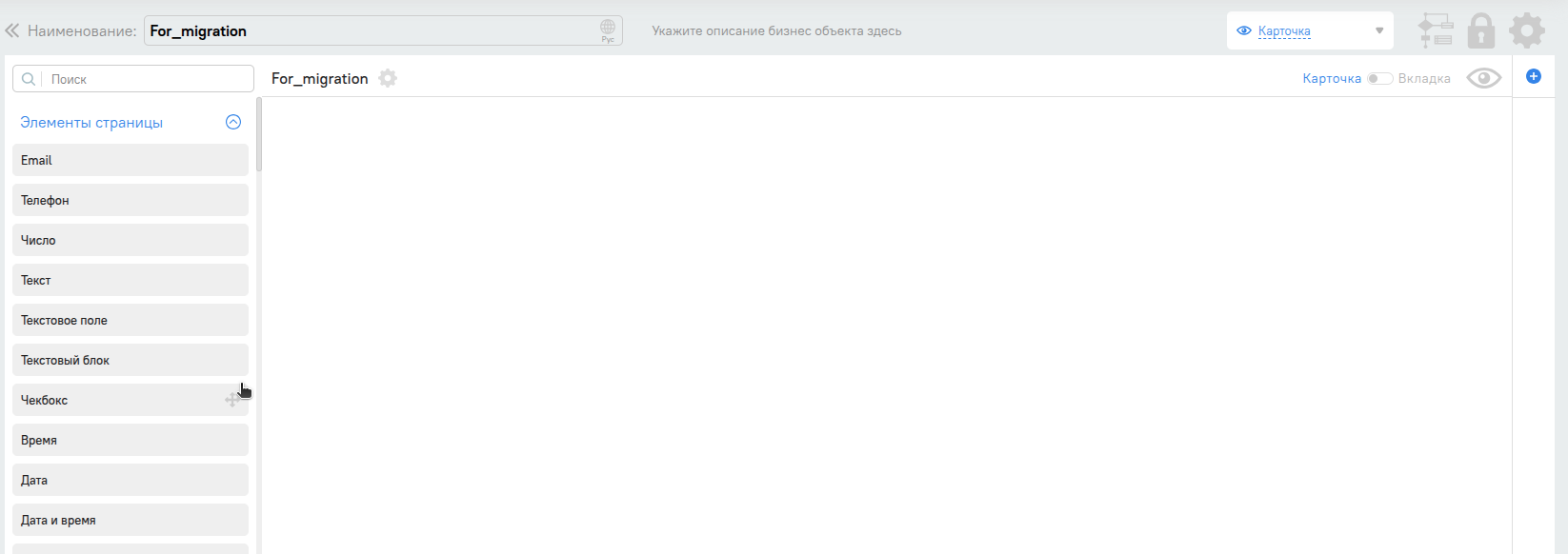
Если поле “Код бизнес объекта” пустое то нажать на карандашик и добавить в поле произвольное название, затем нажать изменить. Кнопка изменить может стать активной не сразу, поскольку система смотрит не пересекается ли бизнес объект еще где-то.
Теперь добавляем первое текстовое поле . Для этого перетягиваем его из списка на правую часть, даем ему название и нажимаем сохранить.
Проверяем появился ли код объекта Для этого в правой части объекта нажимаем шестеренку и пиктограмму с буквой “i”.

В открывшемся окошке мы видим , что код для этого объекта сгенерировался
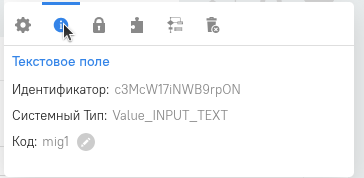
Нажимаем на пиктограмму с пазлом и ставим галочку в чекбоксе “Ключевое поле в IN-миграции”
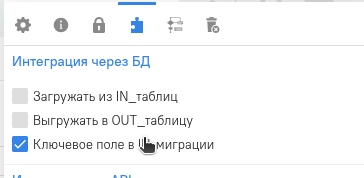
Затем снизу редактора объекта нажимаем сохранить.
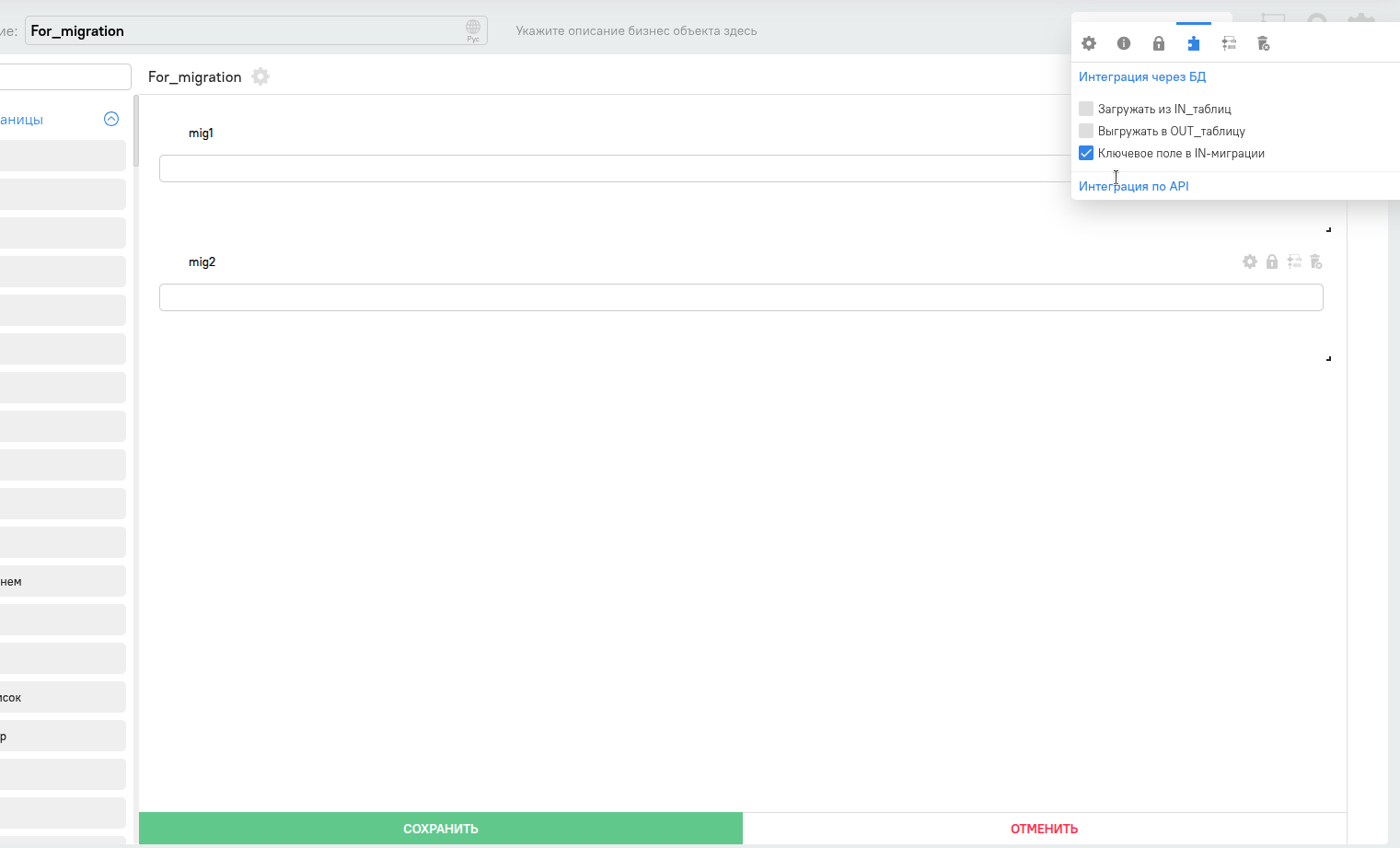
Создаём еще одно текстовое поле таким же образом , но галочку поставить на “Загружать из IN_таблиц” и сохранить

Переходим в zookeeper (Чуть выше написано как это сделать в разделе восстановление zookeeper). И теперь нам надо настроить подключение к БД. Как уже говорилось ранее это может быть внешний сервер баз данных , но в нашем случае мы просто создали еще одну базу данных в текущем сервере, который использует система для своих нужд.
В интерфейсе zk-navigator (web интерфейс для zookeeper) переходим в каталог и открываем /mybpm_v1_3/configs/InMigrationPostgresConfig.txt
Где добавляем информацию о своей БД которая будет использоваться в миграции
В моем случае это выглядит так
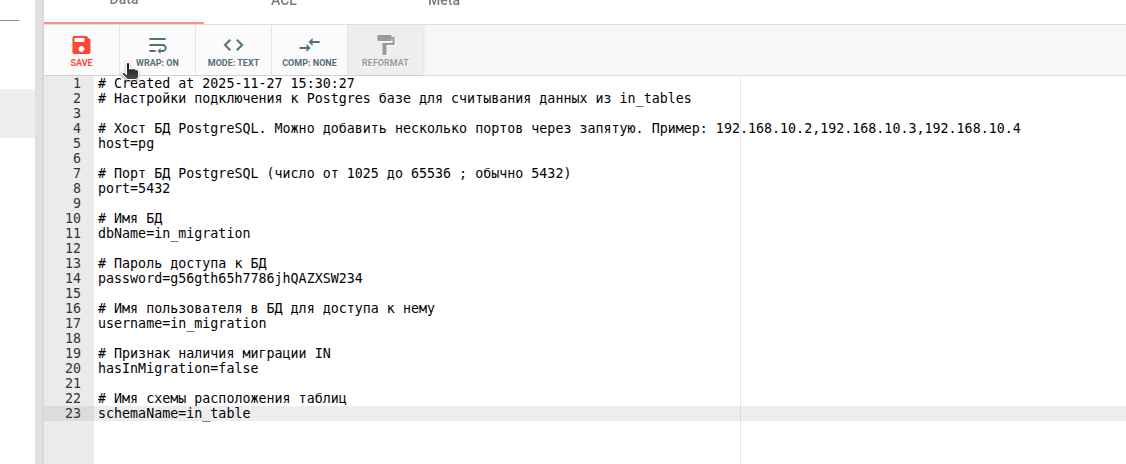
Не забываем после нажать на пиктограмму дискеты , для того чтоб конфиг сохранился и применился в системе.
Следующий шаг - нам надо получить ddl для создания таблиц миграции и для этого надо сделать несколько вещей/
Первым делом мы укажем пароль миграции, это нужно чтоб какой-то сервис не вызвал случайно миграцию и в целях безопасности. Давайте начнем с этого .
Переходим в /mybpm_v1_3/configs/InMigrationConfig.txt
И меняем параметр
passwordToEnableServices=
на
passwordToEnableServices=SuperPuperPass
У вас этот пароль может быть любым удобным вам , с условием соблюдения требований(Они описаны в комментарии выше самого параметра в самом конфиге). Не забываем сохранить изменения кнопкой с пиктограммой дискеты.
Теперь получим сами ddl таблицы , для этого возвращаемся в терминал и подключаемся к pod-у mybpm-api. Чтоб узнать точное имя необходимо выполнить уже известные нам команды чтоб посмотреть имя pod-а , поскольку в нем есть рандомно генерируемая часть.
kubectl get pods -n tcore2
Подключаемся к Pod-у
kubectl -n tcore2 exec -it mybpm-api-849b985458 bash
![]()
Имя пода у вас будет другим.
Далее в терминале самого пода нам надо сделать запрос на получение ddl таблиц
curl 'http://localhost:8080/web/migration/generate-in-ddl?pass=SuperPuperPass&companyCode=NIT3_1'
Где companyCode это параметр который мы посмотрели ранее в “О программе”, а pass пароль , который мы задали только что на предыдущем действии в zookeeper.
После выполнения видим успешное создание ddl
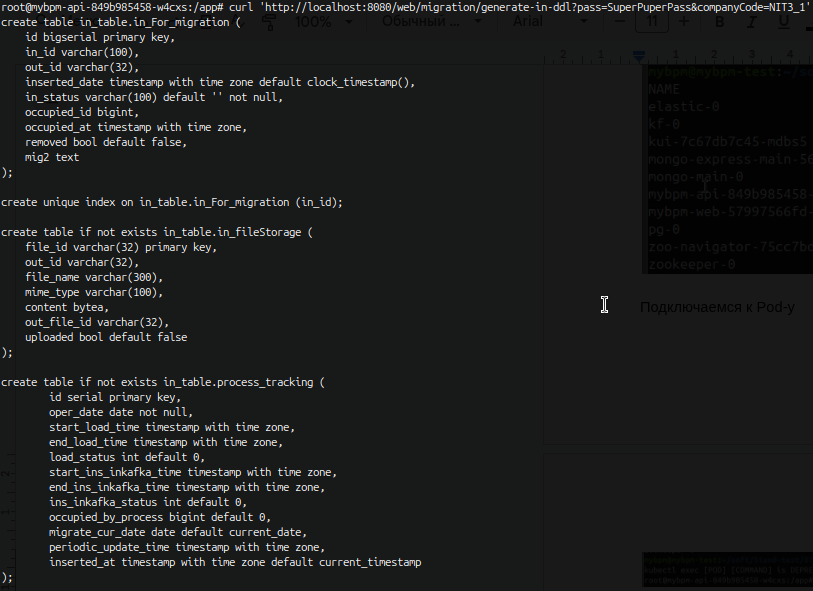
Следующим шагом нам необходимо загрузить ddl , чтоб на их основе создались таблицы миграции . Для этого копируем их в какой-нибудь текстовый документ , я же скопирую сюда.
create table in_tables.in_For_migration (
id bigserial primary key,
in_id varchar(100),
out_id varchar(32),
inserted_date timestamp with time zone default clock_timestamp(),
in_status varchar(100) default '' not null,
occupied_id bigint,
occupied_at timestamp with time zone,
removed bool default false,
mig2 text
);
create unique index on in_tables.in_For_migration (in_id);
create table if not exists in_tables.in_fileStorage (
file_id varchar(32) primary key,
out_id varchar(32),
file_name varchar(300),
mime_type varchar(100),
content bytea,
out_file_id varchar(32),
uploaded bool default false
);
create table if not exists in_tables.process_tracking (
id serial primary key,
oper_date date not null,
start_load_time timestamp with time zone,
end_load_time timestamp with time zone,
load_status int default 0,
start_ins_inkafka_time timestamp with time zone,
end_ins_inkafka_time timestamp with time zone,
ins_inkafka_status int default 0,
occupied_by_process bigint default 0,
migrate_cur_date date default current_date,
periodic_update_time timestamp with time zone,
inserted_at timestamp with time zone default current_timestamp
);
Теперь переходим в консоль postgres
kubectl -n tcore2 exec -it pg-0 bash
su postgres
psql -U in_migration
И теперь копируем ddl из места где вы их сохранили и создаем из них необходимые таблицы.
Результат примерно будет следующий
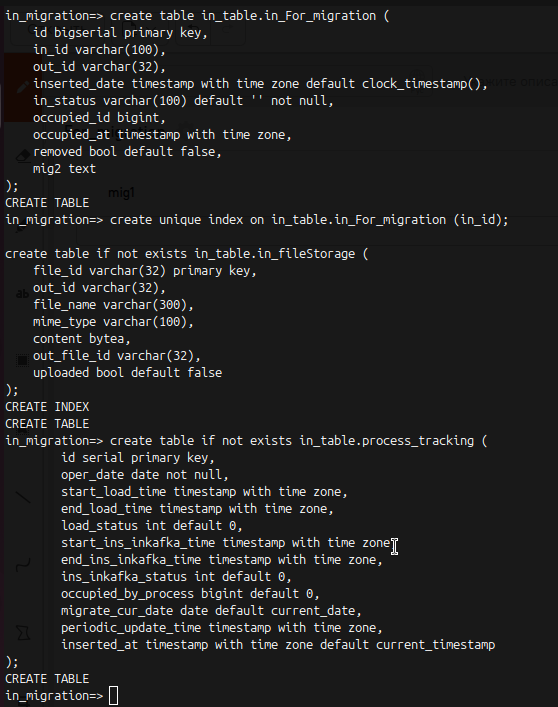
Как видите лучше запускать отдельными блоками, но в целом можно и все ddl одним запросом запустить.
Идем далее
Теперь нам надо запустить в холостую миграцию . Для этого привести к следующему виду конфиги в zookeeper. В /mybpm_v1_3/configs/InMigrationPostgresConfig.txt - в этом конфиге необходимо параметр hasInMigration=false изменить на hasInMigration=true и сохранить изменения. В конфиге /mybpm_v1_3/logging/structure.txt необходимо параметр destination tracer_in_pg_migration to_big_file traces/in_pg_migration, точнее строки ниже него привести к следующему виду (изменить на TRACE).

В конфиге /mybpm_v1_3/configs/InMigrationConfig.txt необходимо подставить код компании (аккаунта) , данные которого мы будем восстанавливать. В моем случае это NIT3_1

Теперь назначаем время запуска миграции в шедуллере /mybpm_v1_3/scheduler/core/InMigrationScheduler.scheduler-config.txt
Приводим вот этот параметр

К такому виду

Сохраняем
Проверим , выполнилась ли миграция , создались ли таблицы.
Проверяем лог миграции.
kubectl -n tcore2 exec -it mybpm-api-849b985458-w4cxs -- tail -n 1000 -f /var/log/mybpm/traces/in_pg_migration.log
Видим результат , который говорит, что миграция прошла успешно (Она холостая , для наполнения уже самих таблиц)
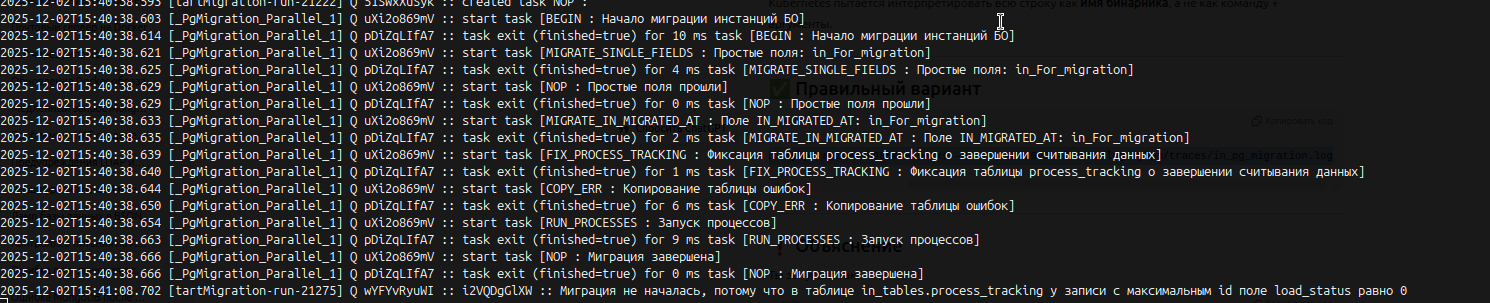
Заходим в postgresql, как делали это выше и выполним
\dt in_tables.*
Из вывода видно , что миграция создала дополнительные таблицы ttt , ttt_postgres и другие для нужд миграции . Все идет хорошо

Теперь нам надо запустить восстановление данных из mongo в остальные базы данных и сервисы , для этого надо перейти в pod mybpm-api
kubectl -n tcore2 exec -it mybpm-api-849b985458-w4cxs -- bash
И Выполнить запрос запускающий восстановление
curl --location 'http://localhost:8080/web/migration/create-mongo-to-kafka-tasks?pass=SuperPuperPass&companyCode=NIT3_1'
Должны получить в числе прочих информационных сообщений подобный вывод , говорящий, что задачи для миграции созданы.

В postgres выполняем (В базе In_migration)
\d in_tables.process_tracking
и видим, что есть запись и в записи есть значение для end_ins_inkafka_time. Что говорит о том, что миграция завершена.

Теперь заходим в интерфейс системы и смотрим восстановленные данные
Все восстановленные данные первое время будут с ярлыками “new”
На примере пользователей
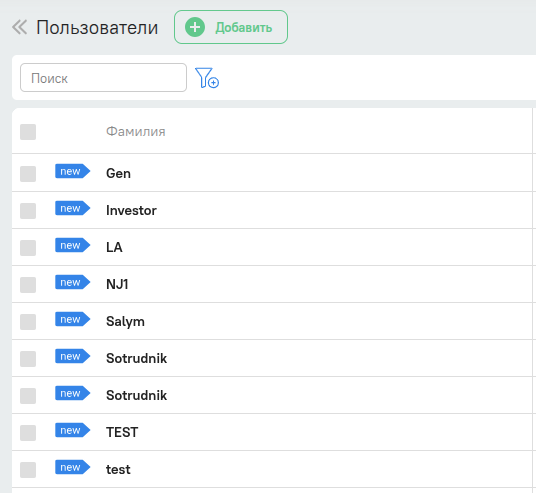
На этом восстановление можно считать успешным .
Затем, если требуется отключить миграцию в /mybpm_v1_3/configs/InMigrationPostgresConfig.
fin